这是一篇充分暴露菜鸟水平低的博客。搬运一下好多人的理论。Embedding的理论博大精深。
从最简单的讲起
敬爱的王老师说过,word2vec的理论方面大有可为,可是呵呵如我的傻逼,慢慢才意识到这是什么意思。看过的一些论文都写的太晦涩了,今天发现一篇一般般的博文(苏剑林同学),一点一点的讲清楚了几个比较重要的问题。原文链接如下:https://kexue.fm/archives/5617。一切的出发点是互信息,中间会和噪声对比估计技术(NCE, noise contrastive estimation)产生千丝万缕的关系。
NLP中的问题多种多样,但是有一个问题比较能讲清楚,那就是我们需要从文本中估计两个实体之间的主题相关性。比如估计“哈利波特”同“霍格沃茨”这两个实体主题相关性。我吐槽一下,这里的分析大多是适用于名词的,因为用名词代表实体再自然不过了。但是动词,介词,形容词等等能够表示一些关系的词语(对应知识图谱里的”relation”和“schema”)我觉得并不适用。你能讲关系之间还有主题相关性么?父子关系,母子关系,爷孙关系这三个关系中到底谁同谁的主题相关性更高一些呢?
那怎么估计实体之间的主题相关性呢?这个基本的工具就是计算两个实体之间的互信息。word2vec就是对这个互信息估计的又快又好。
互信息的定义
在语料中,两个单词$w_1$,$w_2$因为主题相同而一同出现的概率是它们随机出现在一起的概率的多少倍呢?这个量可以用两个单词的互信息度量:
这个量的对数值叫做点互信息(Pointwise Mutual Information, PMI):
一般而言,根据那句名言“看看你跟什么样的人交往,就知道你是什么样的人”来搭建语言模型都是在建模$P(w_2|w_1)$。但是word2vec分析完了之后就发现其实是在建模$PMI(w_1,w_2)$。
条件概率-NCE-负采样-互信息
Skip-gram在优化什么?(条件概率)
下面我会直接给出word2vec中Skip-gram模型建模对象的定义,它反映了词汇和词汇之间的主题相关性。要讲清楚这个量,我们首先对每个词规定用三个量(它在词表中的编号,in向量和out向量)来代表它。比如,将词表中单词分别编号为$1,2,\cdots,i,\cdots,|V|$,那么第$i$个单词可以用$i,u^{out}_{i},v^{in}_{i}$这三种量来代表它。在后文中,为了书写和公式的美观,我会有时用One-hot向量$\mathbb{I}_{i}$来代替$i$。
如此我们便可以定义如下随机变量。对于一个中心词为$w_{c}$的词窗(就是说中心词为词表中第$c$个词),我们将词窗中剩余位置可能出现的单词的词表编号$\mathbf{K}$设为一个随机变量。比如下图中的一个词窗就代表了对随机变量$\mathbf{K}$的一系列采样过程。其中“nlp”是中心词,它的编号是随机变量$\mathbf{K}$的一个参数(因此下面我都用$\mathbf{K}_{c}$来表示这个随机变量)。而”love“,“very”等等单词都是对随机变量$\mathbf{K}_{c}$的采样。显然,$\mathbf{K}_{c}$的取值范围是$\{1, 2, \cdots, |V|\}$等$|V|$个离散的数值($|V|$是词表长度)。
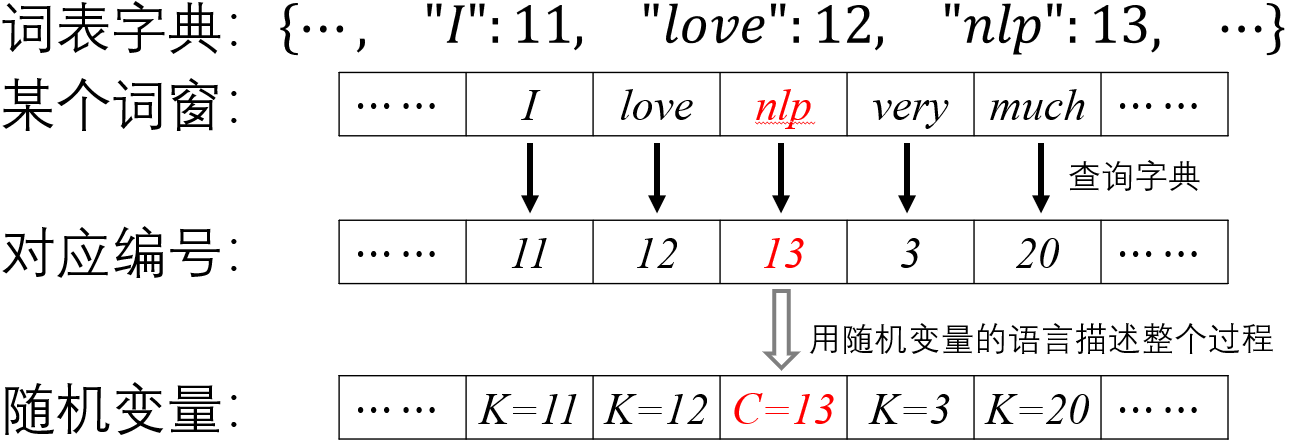
下面列几条声明,任何一条都没有笔误,如果你觉得其中有说不通的地方,那一定是你定义还没有理解正确。
- 对于不同的中心词,比如$w_{c1}, w_{c2}$,它们定义了两个不同的离散随机变量$\mathbf{K}_{c1}, \mathbf{K}_{c2}$。这两个随机变量是否独立,是否有线性关系我们都不知道(就是说定义中没有明确规定或者暗示)。
- 上述离散变量取某个特定值的概率$P(\mathbf{K}_{c}=k)$表示给定了中心词$w_{c}$后,在词窗内出现上下文词$w_{k}$的概率。
一方面我们用$P_{d}(\mathbf{K}_{c}=k)$表示我们希望找到的真实分布,这个分布我们不知道它的概率怎么计算,但是我们可以对其抽样(通过词窗);另一方面,我们假设$P_d(\mathbf{K}_{c}=k)$可以用指数族分布来建模(算是比较常用的一个分布),并且将这个待估计的指数族分布记为$P_{m}(\mathbf{K}_{c}=k)$。指数族分布是符合如下形式的分布:
其中$G(k)$是$k$的某个能量函数,而$Z=\sum_{k}e^{G(k)}$则是配分函数,用于归一化的。上面这个东西和softmax很像(所以粗略的讲,word2vec是在做多分类,每个单词的输入特征是它周围词汇的in向量的加和,输出类别就是当前这个词汇。这是bow模型的意义,和Skip-gram甚至不是同一个建模目标,呵呵呵),但也仅仅是很像而已。Skip-gram没有做任何意义上的多分类任务,它就是要估计上面定义的随机变量所服从的指数族分布中的参数而已。
负采样同NCE之间的关系
这一段是后来补充的,写在这里是为了先给读者一个整体的印象,不写在更前面是因为直到这个地方,符号才刚刚交代完毕。本来在我准备夸夸其谈负采样怎么回事之后,我又不放心,把NCE的原文又翻出来仔细看了一下。这一看发现word2vec同NCE还是有区别的。然后又看了两三天的资料,目前得出的结论是:
- word2vec采用的负采样技术同NCE技术的一部分目的一致,就是为了避免难算的配分函数
- word2vec采用的loss函数同NCE不一样,如果直接应用NCE(完全贴合NCE原文的意思),那么相应的loss函数最后会建模条件概率。就是上面提出的$P_d(\mathbf{K}_{c}=k)$。
- 按照苏剑林同学的推导,采用word2vec本身的loss函数最后会建模互信息,也就是$\frac{P_{d}(\mathbf{K}_{c}=k|w_{c})}{P(\mathbf{K}_{c}=k)}$。其中分子就是$P_d(\mathbf{K}_{c}=k)$,只不过强调了它是条件概率。分母$P(\mathbf{K}_{c}=k)$是单词$w_{k}$本身在语料中出现的概率。
- word2vec收敛性存疑。这里不是指优化word2vec的loss函数时会不会收敛(这个问题是交由Hogwild!算法解决的),这里指的是word2vec收敛到的分布究竟是不是期望的互信息(毕竟苏同学只是在博客上写了写,没有整理发文)。
NCE简化计算并建模条件概率
NCE的原文中对这种方法的描述可以概括成:
- 这是一种新的参数估计手段,目的同最大似然估计(MLE)一致,自然它的结果要同MLE做对比。
- NCE适用于待估计分布中出现了难算的配分函数的场景(就是有一个难算的积分或者求和式),因为这个时候在应用MLE时会理论可行,但实际不可计算。比方说,积分没有显式表达式,高维积分用蒙特卡洛方法又算不准;求和过于庞大,求导解方程不现实等等问题。
- 因此我们应当先描述为什么NCE能做参数估计,再描述为什么它能避开配分函数的问题。
NCE为什么能估计参数
NCE的原文中说这个方法的灵感是一句话:如果我们利用已知的人造分布$P_{n}(x)$,估计出了$\frac{P_{d}(x)}{P_{n}(x)}$这个量,那么未知的真实分布$P_{d}(x)$就被估计出来了。好吧,看着它将简单问题复杂化了,本来$P_{d}(x)$就已经难以计算和估计了,为什么还要去估计更加复杂的$\frac{P_{d}(x)}{P_{n}(x)}$呢?原作者怎么思考这个问题的我还不清楚,但是作者在文章中宣称这样迂回的估计方法能够适用于那些没有归一化的分布(就是估计方法本身不要求被估计量是一个积分等于1的概率分布),从而能够直接估计类似指数族分布中的分子项,绕过了分母中难算的配分函数。所以下面先说怎么从估计$\frac{P_{d}(x)}{P_{n}(x)}$这个量设计出一个二分类的实验来做参数估计。
首先$\frac{P_{d}(x)}{P_{n}(x)}$肯定不是一个概率分布了。如果我们考虑将随机变量$x$固定为$x_{0}$,那么这个量更多的是反映了一种信心:当前这个$x_{0}$是哪个分布生成的概率更大些?因而我们需要设计以下的实验来估计它。
首先对真实分布$P_{d}(x)$做$T_{d}$次抽样得到一系列样本$\mathbf{X}=\{x_1,x_2,\cdots,x_{T_{d}}\}$;接着我们对人造分布(噪声分布)$P_{n}(y)$做$T_{n}$次抽样得到一系列样本$\mathbf{Y}=\{y_{1},y_{2},\cdots,y_{T_{n}}\}$。最后我们定义一个混合模型,设随机变量$U$的采样过程服从下面的规则:
- 首先引入一个隐变量$z$,它服从0-1分布。具体而言$P(z=1)=\frac{T_d}{T_d+T_n},P(z=0)=\frac{T_n}{T_d+T_n}$。
- 每次先对$z$采样,若$z=1$,那么就从真实分布$P_{d}(x)$中采样一个数据,并将该数据作为$U$的一个样本。
- 若$z=0$,那么就从噪声分布$P_{n}(y)$中采样一个数据,并将该数据作为$U$的一个样本。
如此,$\mathbf{X}\bigcup\mathbf{Y}$便可以视作对随机变量$U$进行了一系列的采样后得到的数据集$\{u_1,u_2,\cdots,u_{T_d+T_n}\}$。同时我们对其中的每个数据都打上标签:若数据$u_{t}$采样自真实分布,那么它的标签$C_{t}=1$,否则标签$C_{t}=0$。显然,根据数据集的构成情况,我们有两个先验:
下面考虑两个条件概率,它们很重要。我只写一写第一个条件概率的推导,另一个完全一样:
上式推导过程使用了贝叶斯公式和全概率公式,且没有跳步。这个时候又会分出两个版本的概率:
关于随机变量$U$的真实条件分布,它有待估计,但是概念上应该表示为:
关于我们对$U$进行建模的时候的模型中的条件分布:
显然我这里沿用了前面的符号:$d$表示真实分布,$m$表示模型分布,加上\hat是为了同前面的符号区分开来。接下来,我可以将上面的式子直接同logistic regression联系起来。首先定义$\mu=\frac{T_n}{T_d}$(悄咪咪的告诉你,这个量就是word2vec中的负样本数超参),然后对上式分子分母同时除去$P_{m}(u_t)$得到:
到了这里整个NCE的思路应当就呼之欲出了。下面按照正常的顺序整理一下。
NCE的一般步骤:
按照随机变量$U$的采样规则进行采样,准备好相应的数据和标签。
选择合适的概率模型$P_{m}(\cdot;\theta)$,和噪声分布$P_{n}(\cdot)$,然后将采样得到的数据$u_t$分别代入$P_{m}(u_t;\theta),P_{n}(u_t)$中计算中间统计量(其中$\theta$就是概率模型中待估计的参数):
将中间统计量代入$\sigma(\cdot)$,得到模型基于当前参数$\theta$预测出的标签$\sigma(H(u_t;\theta))$。
计算当前样本得到的likely-hood,并计算交叉熵损失做梯度下降,直到算法收敛得到需要估计的参数。具体而言,模型最后优化的loss函数,在有无穷多样本的条件下可以写作:
上式应当好好考虑一下到底在干嘛,再接着往下读。至于这个算法最后得到的参数同MLE得到的参数一致的数学证明,就需要同学们自己回去看NCE的原文了。
NCE为什么能简化计算
到目前为止,上述NCE的一般步骤中(尤其是第二步)并没有体现出NCE为什么相较于MLE能够简化计算。下面来简单的show一下怎么回事。诀窍就在于$ln P_{m}(u_t;\theta)$怎么定义。这里我就直接举词向量的例子来说明这中间的技巧。同时也是为了方便同负采样技术得到的loss函数做对比。
在词向量的训练中,我们本来假设$P_{d}(k)$能用指数族分布来建模,从而提出了参数待估计的模型$P_{m}(k)=\frac{e^{G(k)}}{Z}$。现在,在词向量的例子中,我们让能量函数$G(k)$由词向量的内积来定义。对于一个给定的中心词$w_{c}$,我们用一个in词向量代表它$v_{c}^{in}$,词表中剩余词汇$w_{k}$(上下文词)我们用它们的out词向量$u_{k}^{out}$来代表。如此我们便可以将$G(k)$形式化的定义为下面的函数(借助了One-hot向量表示,PS这里符号不够用了,$U$不是上面那个混合模型对应的随机变量了,而是out向量组成的矩阵)
显然,中心词的in向量和剩下所有词的out向量就是随机变量$\mathbf{K}_{c}$所服从指数族分布的待估计参数,记作$\theta$。那么我们可以将$P_{m}(k;\theta)$详细写成:
然而,要想让NCE发挥出简化计算的威力,我们不能这么定义上面的$P_{m}(k;\theta)$。我们应当按照下面的套路直接定义出$\ln P_{m}(k;\theta)$:
上面新定义出来的
就是原作者口中的没有进行归一化的分布。同时新定义出的$\gamma$也是一个待优化的标量参数(用一个随机数初始化)。也就是现在除了要估计原来的参数$\theta$,我们还得估计$\gamma$。采用NCE原文中的符号,就是我们需要估计增广参数$\hat{\theta}=\{\theta,\gamma\}$。显然将(13)式代回到原来NCE的框架中没有任何违和,所以我们依然得到了原始模型中需要估计的$\theta$,以及一个新得到的$\gamma$。作者宣称这样得到的$\theta$就是我们本想要的$\theta^{\prime}$并且最终得到的$\gamma$回满足
请大家好好想一下这个宣称到底什么意思。作者的原意是,因为配分函数在原始模型中最后就表现为一个固定的常数,所以我们直接靠$\gamma$来估计这个常数最后会是什么值。如此,NCE通过上面灵巧的定义,并没有直接计算配分函数,但是最后依然把它估计出来了。
最后,我终于可以将直接应用NCE方法得到的词向量模型的loss函数给写出来了,以供后面对比。
NCE建模了条件概率
苏剑林同学给了一种推导过程能很直观的告诉你上面的优化式什么时候取得最优值。我这里用一下他的方法。首先将loss函数中的期望用积分代替。这就使得它变成了:
因为$P_{d}(k),P_{n}(k)$同增广参数$\hat{\theta}$无关,所以可以将上面的loss改为下面的形式,而不会影响最后的优化结果(你可以从下式拆开后往回推,我就是这么搞得,我现在也不明白苏同学怎么想到的,膜一下):
上式第二项是非负的KL散度,显然当loss被充分优化后(比如变成0了),我们有:
将$y=0,1$的两种情况展开写,然后相互除一下会有:
最后,引入经过实验实证的假设:$\gamma=0$、通过移项并代入上面关于$\ln P_{m}(k)$的定义就会有:
就是说最后词向量之间的内积是条件概率的对数值:
负采样建模了点互信息(PMI)
鉴于这篇博文已经这么长了,我真的不想写了,所以请特别熟悉word2vec的同学直接接住我抛出来的word2vec的损失函数:
可见,负采样同NCE最重要的区别(我的观点里)在于$\ln P_{m}(k;\theta)$中是否包含噪声分布的参与(负采样就是没有噪声分布的参与)。但是注意,真实分布$\hat{P}_{d}(1|k)$中还是有噪声分布参与的。所以类似的,我们能推导出:
稍加变形就能得到:
注意到word2vec原文中设置了噪声分布为$P_{n}(k)\backsim P(w_k)$,i.e.和$w_k$自身在语料中出现的概率成正比。所以通过适当的缩放噪声分布就可以得到:
上式终于完成了惊为天人的联通,将词向量的内积同PMI这样的统计量直接联系了起来。
论文佐证
翻了一下以前看过的一篇论文,发现我得出的结论和它不谋而合啊(但是这哥们推的贼叫人看不懂)。贴个图。

最后的疑问
花了这么久的时间来推导上面那个式子,我还是不幸的注意到这个结果同实际应用中还是有一个说不过去的鸿沟,那就是上式是in向量和out向量的内积,但是实际中大家只会用其中的某一个而不是两个一起用。就是实际应用中只会出现
我试验过,如果建模的时候强行只用in向量,而没有out向量,效果会变差。
为了回答这个问题,我近日又做了很多的尝试。比如,我渐渐意识到$v_j^{in}*v_i^{in}$为啥内积会大会小呢?肯定是(?这么笃定?)因为$P(K_i)$与$P(K_j)$这两个分布本身非常相似。我决定具体的show一下$P(K_i)$与$P(K_j)$的相似性是如何塑造了$v_j^{in}$与$v_i^{in}$的相似性。
一条不一样的道路
最近又把2016年马腾宇(姚班出身,普林斯顿博士,斯坦福AP)大佬在他得了ACM最佳博士论文奖提名的博士论文中关于词向量的一些结论拿出来看了一遍,发现了他处理上述疑问的步骤:通过求联合概率分布时,对中间变量in向量进行积分,从而消去这些讨人厌的东西,直接得到联合概率分布同out向量之间的关系,最后导出了PMI同out向量内积间的关系。
我这里来快速尝试一下,把他的思路改造到我这边来:
出发点在于在skip-gram加上负采样技术下,如何建模并估算两个单词的联合概率分布:通过引入第三个单词作为“主旨词”,然后对该主旨词进行积分(马大佬搞了两个“主旨词”,我这里只用了一个,神似神似,嘿嘿嘿):
上面的公式就对应了马大佬的公式(7.2.6),神似神似。上式每一步我都是很小心的在变换,保证有理有据,符合skip-gram和负采样模型本身的定义。首先第一步可以粗浅的理解为全概率公式,但是我还是得啰嗦两句,这个全概率公式用得很贴合模型;第二步就是数学期望的定义;第三步用了独立假设,这个独立假设也是符合skip-gram本身的实际做法的。后面就是代入定义而已。另外,这里用的独立性假设可以陈述为:
但是这绝不意味着我们假设了$p(w_{i},w_{j})=p(w_{i})*p(w_{j})$。这一点你可以自行检查。下面为了将配分函数拿到期望外面,我们插播马大佬的“中央lemma”。这条lemma的意思是对于绝大多数的中心词$v_{k}^{in}$而言,其对应的拿个配分函数的值都落在一个固定值$Z$附近。这条lemma定量的给出了这个情况不成立的概率。
插播马大佬整出来的有用lemma
若out向量满足$u_{i}^{out}=s_{i}\times\hat{u}_{i}^{out}$,其中$s_{i}$是一个随机变量,决定了该向量的模长,$\hat{u}_{i}^{out}$是一个单位模长的随机向量,服从球状高斯分布;in向量满足单位模长,且在单位球面$\cal{D}$上服从均匀分布,$\hat{v}_{k}:=\frac{v_{k}^{in}}{|v_{k}^{in}|_{2}}\backsim U(\cal{D})$。那么对于大部分in向量$\hat{v}_{k}$其对应的配分函数$Z_{k}$都会以很大的概率满足
其中$\epsilon_{z}=\hat{O}(1/\sqrt{n})$,并且$\delta=\exp(-\Omega(\log^{2}{n}))$,n为词表长度。
注意到词表长度$n$是一个很大的数字(比如九百万这种),所以$\epsilon_{z}$和$\delta$都很小:前者意味着$Z_{k}$分布的很集中;后者意味着这种情况的概率很大。这条lemma的证明可以看这篇博文的附录,证明中的各种concentration技巧轮番登场。
现在,为了保证思路的流畅性,我们暂且接受这个结论,那么我们就能够进一步计算公式(30)。具体而言,我们首先将$P_{m}(i;k)$的能量函数的定义修改为:$P_{m}(i;k)\propto\exp(u_{i}^{out}*\hat{v}_{k})$,并且其中中心词in向量$\hat{v}_{k}:=\frac{v_{k}^{in}}{|v_{k}^{in}|_{2}}$。代入公式前,我们强调一下关于中心词的两个分布:中心词$k$本身在语料中出现的概率$k\backsim p(w_{k})$,以及中心词$k$对应的in向量$\hat{v}_{k}$在嵌入空间$\cal{D}$中服从均匀分布$\hat{v}_{k}\backsim U(\cal{D})$。这两个分布的关系很重要,决定了期望最后到底等于啥。
显然只有$Z_{k}$满足中央lemma描述的集中现象时,我们才能将之视为一个常数,所以我们将这个事件定义为$\cal{F}$。那么规定$\mathbf{1}_{\cal{F}}$表示事件$\cal{F}$发生,$\mathbf{1}_{\cal{\bar{F}}}$表示未发生。将这些符号代入公式(30):
通过$\mathbb{E}_{k\backsim p(w_{k})}(\mathbf{1}_{\cal{\bar{F}}})=\Pr[\cal{\bar{F}}]\leq\exp(-\Omega(\log^{2}{n}))$,能够证明$T_{2}$项可以忽略不记(这一步的证明,马大佬说还是很难的,所以证明见本博文附录)。如此我们便可以开开心心的将第一项中的$Z_{k}$,以可控的误差,当作常数拿到期望外面:
下面就是最牛逼的一步了:通过积分消去$\hat{v}_{k}$。
首先我们宣称随机变量$x:=(u_{j}^{out}+u_{i}^{out})*\hat{v}_{k}$近似服从正态分布!这个宣称可是一个很大胆的宣布,需要很多的思考和证明;然后利用著名的微积分习题:
来消去$\hat{v}_{k}$。因为在$x$所服从的正态分布中,那个$\sigma$只和$u_{j}^{out},u_{i}^{out}$有关而和$\hat{v}_{k}$无关。所以接下来我需要说明,为什么$x$近似服从正态分布,需要什么条件才能近似服从正态分布,以及相应的严格证明。为了更加清晰的展现思路,我把下面两节内容的关系浓缩在一串等式中:
显然第二个等号(打了很多问好的那个)讨论的是什么条件下$x$才能近似服从正态分布,这个步骤在马大佬论文里是对隐变量的一个假设,我们这里没有引入隐变量,所以需要严格的讨论到底成不成立;第四个等号讨论的是$x$为什么会近似服从正态分布,这一步骤是马大佬在博士论文里写的。
为什么内积服从正态分布
严格说来内积并不是服从正态分布,而是服从学生分布。学生分布算是正态分布的厚尾版本。那是怎么得到这个学生分布的呢?很简单,不停重建坐标系就行了。比方说,在求期望的过程中,$u_{sum}^{out}$ 是固定不动的,那就以这个向量的方向为一个坐标轴,建立坐标系。然后 $u_{sum}^{out}\hat{v}$ 就变成了$\hat{v}$在$u_{sum}^{out}$ 方向上的一个投影。因为$\hat{v}$ 是一个在球面上均匀分布的单位向量。所以$\hat{v}$ 可以按照如下的方式生成:首先让$\hat{v}$ 的各个坐标服从标准正态分布,并记它在$u_{sum}^{out}$ 的方向上的坐标为$x$ ,剩下的维度组成一个低一个维度的向量$y$ ,那么$\hat{v}$ 在单位化之前的模长就是$|\hat{v}|_{2}=\sqrt{x^2+|y|_{2}^{2}}$ 。第二步,我们需要将$\hat{v}$ 单位化,就得到了一个在球面上服从均匀分布的单位向量。此时$\hat{v}$ 在$u_{sum}^{out}$ 方向上的投影就变成了$\frac{x}{\sqrt{x^2+|y|_{2}^{2}}}$ 。因为$\hat{v}$ 的维度相对较高,所以$\sqrt{x^2+|y|_{2}^{2}}$ 可以用$|y|_{2}$ 来近似。而$|y|_2$ 就是一串服从标准正态分布的随机变量的平方和开根,这就是$\chi^2$ 分布的定义。所以通过适当的建立坐标系,总是可以将$u_{sum}^{out}\hat{v}$ 表示为一个服从标准正态分布的随机变量$x$ ,除以一个服从$\chi^2$ 分布的随机变量$|y|_2$ , i.e., $u_{sum}^{out}*\hat{v}\approx\frac{x}{|y|_2}$ 。而这个$\frac{x}{|y|_2}$ 就是学生分布的定义。有了这个认识为基础,那么对$\hat{v}$的期望就可以通过建立坐标系变成对这个学生分布在$[-1,1]$ 上求期望。这个期望和对高斯分布求期望的误差很小。所以说内积近似服从正态分布。
什么时候内积服从正态分布
前面提到,我们需要$\hat{v}_{k}$在球面上服从均匀分布,那我们就得问一个问题:这能办得到么?有很多因素暗示我们这一点办不到。比如,原始的单词$k\backsim p(w_{k})$可不是服从均匀分布的,为什么我们就能期望该单词的嵌入$\hat{v}_{k}$就是球面上的均匀分布呢?下面这个例子很有启发性,它暗示了这个问题能不能办到,应该怎么办到。
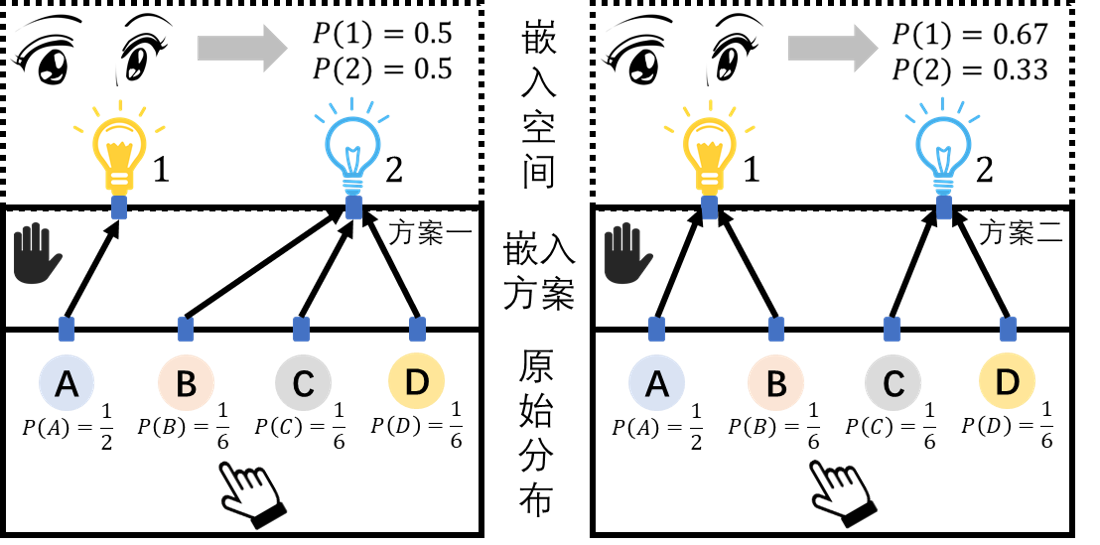
如图所示,我们做一个实验来讨论上面这个问题。假设实验中有4个按钮A,B,C,D。我的左手会以不同的概率去按这些按钮:
然后我还有右手来接线:将这4个按钮分别连接到两个灯泡上,一个按钮只连一个灯泡,按到哪个按钮,该按钮对应连接的灯泡就会亮。我们规定两个灯泡各自有一个编号,比如1号灯泡和2号灯泡。接着我们就可以说,连线的过程就是对4个按钮进行“嵌入”的过程:如果按钮A连上了1号灯泡,就称A的“嵌入”是1;如果按钮B连了2号灯泡,就称B的”嵌入“是2。各种不同的连接方案就对应了不同的”词嵌入“算法。灯泡集合$\{1,2\}$就是”嵌入“空间。最后我的眼睛观察每次按过一个按钮,哪个灯泡会亮(在我看不到左手到底按了哪个按钮和具体的连接方案的情况下)。
显然每次按一个按钮就对应一次在嵌入空间中的采样。依照方案一,观察者会相信这个空间中的随机变量”点亮的灯的序号k“服从”均匀分布“,i.e. $P(k=1)=P(k=2)=0.5$;依照方案二,观察者会认为$k$服从某种伯努利分布。所以这个例子告诉我们:1)离散情况下有可能可以办到我们的要求;2)且嵌入的方案决定了如何办到均匀分布的要求;3)最后嵌入的支撑集空间要远小于原始分布的支撑集空间。那么除了这种离散的toy example,在真实的词嵌入语境下,我们还能办到么?对应的数学问题该如何抽象?我觉得可以这样抽象这个问题:
假设离散随机变量$X$有$n$个不同的取值,并且$X\backsim P(X)$,而后将它代入嵌入函数$f$后得到新的随机变量$Y=f(X)\in\mathbb{R}^{d}$,接着我们把$Y$的支撑集均匀分为$d$等份(自然是按照支撑集上的自然测度),分别在这$d$等份上对$Y$所服从的分布做积分得到离散分布$P(\bar{Y})$,试寻找最佳的嵌入函数$f^{*}$,使得$P(\bar{Y})$尽可能是均匀分布。用数学语言描述就是:
上面这个式子还不够用,因为不能用梯度下降去优化它。
一条理论很好看,但是实现很困难的路
有了上面的例子的直观启发,我们需要突破一下原有的skip-gram的建模思路。比如说,原始的skip-gram模型为了对$p(w_i|w_j)$和$p(w_j|w_i)$同时建模(这两个量是不相等的),所以不得不给每个单词两个向量$\hat{v}$。
一个三维嵌入的例子
假设我们嵌入的维度是3,那么讨论的问题就变为:如何在三位球面上嵌入向量使得它们近似服从均匀分布。我决定先调查一下如何在球面上均匀的生成随机点,也许会有一些启发。一个自然的想法是用球坐标系来抽样。一个三维球面上的点$(x,y,z)$可以用球坐标系表示为:
所以可以猜测,如果让$\theta,\phi$服从均匀分布,那么就可以在三位球面上均匀生成点了?
猜错了。实际上这样子生成出来的点会在两个极点处很稠密(也就是概率密度很大),远不是均匀分布。为什么呢?因为在靠近极点的位置($\theta=0,\pi$),球面的单位元面积:
词类比不是扯淡
这两天在不断搜索Zipf law和Uniform distribution的时候,把Skipgram - Zipf + Uniform = Vector Additivity(2017 ACL)认真看了一下。还是很好的一篇文章的,虽然啥实验都没有,但是还是用简单的式子和精巧的定义讲清楚了一些概念。作者写那篇文章的时候已经是AP了,PHD在CalTech念的计算数学。作者在文章中对词向量的一些理解和我的理解还是一致的。此外他还特别讨论了关于$\frac{v_{i}^{in}}{|v_{i}^{in}|_{2}}$的一些结论,启发很大。
如何定义同义词?
本文的核心概念是如何界定“同义转述”。他给出了一个数学上的定义:对于一堆词$w_{1},\cdots,w_{k}$,它们的意思如果可以用一个词$w_{i}$表示,那么就说$w_{i}$ “paraphrase”了这一堆词$w_{1},\cdots,w_{k}$。那如何表示这种现象呢?我们可以从条件概率入手:如果对于词表中剩余的每个词$w_{j}$,
都成立,那就有很好的理由相信这种现象发生了。但是上式过于严格,可以放松一下要求:
那么上式求得的最优解$\hat{w}_{i}$就是最接近$w_{1},\cdots,w_{k}$意思的那个单词。围绕这个简单的式子,作者写道:1)我们不知道怎么计算$P(\cdot|w_{1},\cdots,w_{k})$;2)上式何时取到最小值?
为了能够顺利的讨论下去,作者结合Skipgram模型本身做了两个比较合理的假设:
- 巴拉巴拉
- 巴拉巴拉巴拉
最后通过这两个假设简化了计算,通过求梯度为零,发现如果满足下式,就会取到最小值:
作者给上式起了名字,表示它是一种同义转述的操作。这个时候再加上对词频分布不是Zipf律而是均匀分布的“极不合理”假设后,上式能进一步简化为
基于上面的式子和上上面的式子就能轻松得到词类比的公式。